
Weekly Readings #11
Published:
Distillation and cloning; onboard swarm evolution; The Mind’s I chapters.
📝 Papers
Czarnecki, Wojciech Marian, Razvan Pascanu, Simon Osindero, Siddhant M. Jayakumar, Grzegorz Swirszcz, and Max Jaderberg. “Distilling Policy Distillation.” ArXiv:1902.02186 [Cs, Stat], February 6, 2019.
Policy distillation is a powerful method for speeding up the optimisation of agents, improving their generalisation and enabling training of architectures not amenable to direct reinforcement learning. A wide variety of mathematical formulations and algorithms have been proposed, with drastic differences in the objective being optimised and the resultant performance. This paper offers a survey and proposes modifications for improving performance.
The learning objective for policy distillation is usually some combination of:
- Similarity between the teacher and student policies at a given timestep, commonly measured by Shannon’s cross entropy between the two distributions over actions over a set of trajectories. This captures short-term alignment.
- A reward term responsible for longer-term alignment, for example by looking ahead to the next timestep and measuring policy similarity again.
The main point of divergence between policy distillation methods is the data used for training. In general, the dataset can be comprised of trajectories sampled from the teacher (off-policy / teacher-led) or from the student but labeled by the teacher (on-policy / student-led). Theoretically, student-led training is not always guaranteed to be convergent because commonly-used update equations do not correspond to valid gradient vector fields. This can be rectified by adding a carefully-constructed extra term [see paper for details].
This is a great result, since empirical results suggest that, if convergent, student-led training produces stronger policies. Intuitively, this makes sense since we ultimately evaluate performance on the student distribution. Additionally, if the teacher policy has low stochasticity, training using samples from it means only a small fraction of the state space is reached. Any small divergence from this narrow region is likely to be compounded due to a lack of training data.
There are some caveats to this, however:
- If we are interested in performance across the entire state space, training on random trajectories across this space is best. This is rarely practical.
- If we are interested in fidelity with respect to the teacher [for explainability?], training on the teacher distribution is best.
Grover, Aditya, Maruan Al-Shedivat, Jayesh K. Gupta, Yura Burda, and Harrison Edwards. “Learning Policy Representations in Multiagent Systems.” ArXiv:1806.06464 [Cs, Stat], July 31, 2018.
Modeling agent behaviour is important for understanding complex phenomena in inhomogenous multi-agent systems. Here the task is framed as a representation learning problem and an encoder-decoder model is used to learn continuous representations of diverse agent policies based on observations of several episodes of interaction.
The Markov game formulation is used throughout this paper; this is an extension of a POMDP for multiple agents with different action and observation spaces. It is further extended by augmenting agents’ action spaces with a null action, for which no reward is received. Forcing a subset of the agents to be inactive (take the null action) for a given episode allows for games in which all agents do not participate simultaneously (such as one-vs-one tournaments). Throughout this paper, $k=2$ agents are active in each episode.
Policy representations are learned by an encoder-decoder model. The encoder, parameterised by $\theta$, maps an agent’s observation [consisting of? not clearly communicated] to a real-valued vector embedding. The decoder, parameterised by $\phi$, maps the vector into an action. The objective used for learning is a weighted sum of two components:
- Generative: the predicted action should match the true action taken by the agent.
- Discriminative: state embeddings from two episodes where the same agent is active should be more similar than another one where the agent is not active. This is quantified using a triplet loss.
Jones, Simon, Alan F. Winfield, Sabine Hauert, and Matthew Studley. “Onboard Evolution of Understandable Swarm Behaviors.” Advanced Intelligent Systems 1, no. 6 (October 2019): 1900031.
A nine-robot swarm with significant processing power is used for rapid onboard evolution of control policies, which is desirable as it closes the reality gap. Policies are implemented as behaviour trees (BT), facilitating understanding, querying, explanation and manual modification.
The specific task considered here is based on foraging: the robots must push a plastic frisbee in the $-x$ direction. The fitness function is the time-averaged $-x$ speed of the frisbee, normalised by the maximum speed of the robots, with additional penalties if no movement at all occurs, and if the evolved controller size exceeds a memory threshold.
An island model of evolution is used, whereby each robot in the swarm runs an evolutionary simulation, with the winning tree from each generation being broadcast to the rest of the swarm for inclusion in their subsequent generations. There is no requirement for the robots to be synchronised in this process. Every two minutes, each robot updates its actual controller tree to the fittest one generated by its onboard evolution. Thus, the real swarm has a heterogenous but related set of controllers.
After running the experiments, performance is analysed by clustering behaviour segments according to a number of hand-crafted metrics (e.g. average robot speed, average acceleration, degree of alignment between orientations, degree of ‘loitering’ far from the frisbee).
Individual behaviour trees are also analysed. First a series of reduction transformations are applied to produce significantly more compact trees with identical functionality. Then behaviours are manually investigated, described and visualised. Then a small number of decision thresholds of a high-performing tree are manually tuned, leading to a $10\%$ performance improvement in simulation.
Traoré, René, Hugo Caselles-Dupré, Timothée Lesort, Te Sun, Guanghang Cai, Natalia Díaz-Rodríguez, and David Filliat. “DisCoRL: Continual Reinforcement Learning via Policy Distillation.” ArXiv:1907.05855 [Cs, Stat], July 11, 2019.
The DisCoRL method is proposed for distilling policies from three simulated 2D navigation tasks into a single model that can automatically infer which one to run. The model is then tested in a real-world environment.
For each task $i$, a state representation encoder $E_i$ maps a high-dimensional observation $o_t$ (image) into a low-dimensional vector $s_t$. The encoder is trained on data sampled using a random policy, as a combination of an inverse model (predict $a_t$ given $o_t$ and $o_{t+1}$) and an autoencoder (reconstruct $o_t$ from $s_t$).
The SRL stage greatly improves sample efficiency for the second stage: distillation to clone a policy $\pi_i$. Two different training datasets are compared:
- Trajectories generated by $\pi_i$.
- Trajectories generated by a random or exhaustive search policy, but labeled with an action distribution by $\pi_i$.
The former is found to be far more robust. In addition, KL-divergence between the action distributions of the teacher and student policies (temperature $\tau=0.01$) proves to be a slightly better loss metric than the MSE. The three policies ($i=1,2,3$) are distilled into a single policy model [I assume through iterative training?]
In deployment, the agent must select the appropriate representation encoder for each task, which is made simple in the chosen experiment (navigation (1) to; (2) around; (3) away from a target marker) because the marker has a different colour in each case.
Zhan, Eric, Stephan Zheng, Yisong Yue, Long Sha, and Patrick Lucey. “Generative Multi-Agent Behavioral Cloning.” ArXiv, 2018.
Propose this technique to learn a non-deterministic multi-agent policy from passive observation of demonstrations. The policy representation is hierarchical, allowing complex behaviours and long-term plans to be captured. The technique is applied to learn offensive team strategies in basketball (the ball and defensive players are excluded from the simulations).
Policies are learned by a variational autoencoder, modified so that it is conditioned on the hidden state $h$ of an RNN. At time $t$, the input is the environmental state $x_{t-1}$. An intermediate layer of the model is used to model macro-intent variables $g$, intended to encode long-term intent of the $K$ agents (in the basketball context, these are regions of the basketball court to move towards). All macro-intent variables are effectively visible to all agents, since it is these that are mapped by the RNN into the parameters of a multivariate Gaussian over the $K$ actions / next states.
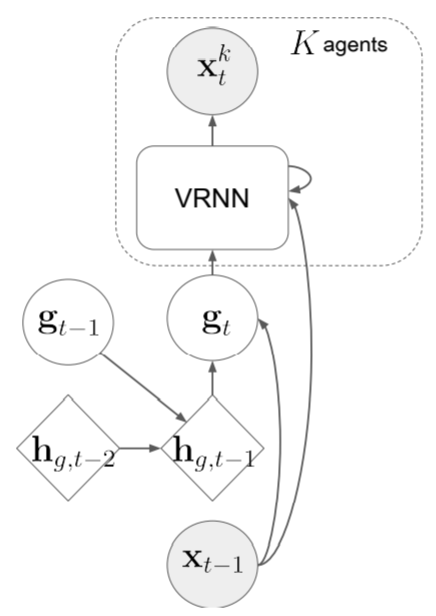
Rather than training end-to-end, better performance results from training the macro-intent and action mappings in separate supervised learning stages. Manual expert labeling could be used to generate a dataset of macro-intent variables, but to reduce the time expense, weak labels are generated through a number of simple heuristics.
📚 Books
Dennett, D. & Hofstadter, D. (2001). The Minds’ I: Fantasies and Reflections on Self and Soul. Basic Books.
A Sense of Self
A fundamental change of perspective occurs when I realise that a person being talked about is me. While during most of my life I suppress this fact, there is an irreconcilable difference between the nature of other people (their status as a part of the objective world, their mortality, their ownership of a head…) and that of myself.
While the biological sciences have rushed to explain the mind in ever more reductionist, physical terms, quantum physics has led us to a view of the universe in which subjective observation is itself fundamental, perhaps more so than the objects of observation themselves. Is our whole scientific worldview at risk of becoming one big circular definition?
Soul Searching
In Computing Machinery and Intelligence, Turing introduces his imitation game. For many kinds of entity (weather, milk, travel), an imitation/simulation is clearly different from the thing itself, but for others (music, mathematical proof) it seems just as good. On which side does the mind fall?
The location of the divide seems to have something to do with the effect that the imitation has on in the external world, as compared with the actual entity. But reasoning along these lines could lead us to animist conclusions, projecting ‘selves’ and ‘souls’ onto sufficiently complex robots.
From Hardware to Software
An excerpt from Dawkin’s The Selfish Gene presents the idea that from an evolutionary perspective, humans and all other organisms are mere temporary survival machines for the long-lived replicators that are our genes. Natural selection is a competition for stability, and cells, organs and bodies are an elaborate means of achieving it. But alongside greater sophistication, genes have had to accept less direct control over the behaviour of their survival machines. They are now more like the creators of a chess playing program than the drivers of a car, exerting their influence as heuristics and biases rather than commands.
🗝️ Key Insights
- A general rule for inverse learning: train on samples from the distribution you’ll be evaluating on. If the aim is to clone a teacher within its range of operation, train on samples from its policies (teacher-driven). If the aim is to produce a robust policy, train on samples from the learned (student-driven).
- Behaviour trees seem to be an extremely powerful and explainable model for agent policies, which can trained by evolution.
- Given the right task-specific representation mappings (e.g. from an autoencoder), a single policy model can be used to solve multiple task variants. This suggests the learned state representation space is rather general.
- I’ve previously seen how learning representations and policies separately can improve efficiency and generalisation. It appears the same is true of hierarchical policy learning; in fact, ‘macro-intent variables’ play a functionally very similar role to condensed representations from SRL.
- A thought from the first few chapters of The Mind’s I: from the perspective of our genes, we are effectively a misaligned AGI.